


The Max Planck Institute for Legal History and Legal Theory (mpilhlt) has recently approved its Research Data Policy. In accordance with this document, our institute commits to systematic management of research data in line with established standards and best practices, thus assuring the quality of research, satisfying legal and ethical requirements and contributing to the responsible handling of resources. This blog series will bring you up-to-date with the main concepts of research data management and explain how you can benefit from implementing them into your research project.
Read Part 1 “What is Research Data Management and Why it Matters” here
Research Data in Legal History: Are We All Digital Historians Now?

We are all dealing with an increasing amount of digital research data these days, even those of us doing research in a classic way – by reading books, going to archives, and analysing our sources. You do not need to be in a digital humanities project to actively engage with data. If you use a computer for your research, there is a high chance you are already producing, collecting, analysing, etc. digital research data. And you need a way to handle it professionally.
What is Research Data?
But first, let us get some important things clear: what is research data in the context of legal history? And, more importantly, what is your research data? Before we delve into these questions, let me preface them by pointing out that when we speak about research data in the context of RDM, we always speak exclusively about digital research data. This digital research data can either be a result of a digitization process (as in the case when we digitize a printed book or an archival document) or born as a digital object (meaning it was originally created in digital form). Any analogue representations of data (like your handwritten notes scribbled on the margin of a document) are outside the scope of RDM as long as they stay analogue.
To return to the questions posed, there is no doubt that, depending on the project’s context, almost anything can be considered research data. For example, Kindling and Schirmbacher defined research data in their 2013 essay this way:
We define digital research data […] as all digitally available data that is created during the research process or is its result.
This definition is not very helpful to us as researchers in legal history, as it is very broad: everything that is created or used and reused during research can potentially be research data. Instead of trying to define research data for legal history overall, it will be much more useful to look at your own project: what serves as research data in your case will depend on your research question, the field, and the methods you use. Just think about your primary sources. In most cases, they will be your data. Do you work with digitised archival materials? Or maybe with digitised first editions of Early Modern prints? Do you analyse documentary pictures or audio-visual material? How about maps? Do you use any online tools or databases like the one here to track down your sources? Do you reuse any online material produced by other researchers? And what about when your sources are not available online? In that case, you may be producing the data necessary for your research yourself: by going to the archives and taking pictures of the sources, by using automatic character recognition tools like Transkribus to transcribe your material, by taking interviews for your research, by creating a catalogue or registry of a historical phenomenon or event in a spreadsheet, by taking notes on your laptop and annotating your sources – and in a hundred other possible ways. Try to look at your research from a data perspective: do you actively engage with any primary sources in digital form? Do you analyse material available online? Or do you produce your research data yourself by digitising sources or creating new digital material?
Research Data Life Cycle: a Virtuous Circle
Now that we have established what may serve as research data in legal history, it is time to take a look at the research data life cycle at different stages of a research project and how RDM comes into play at each phase.
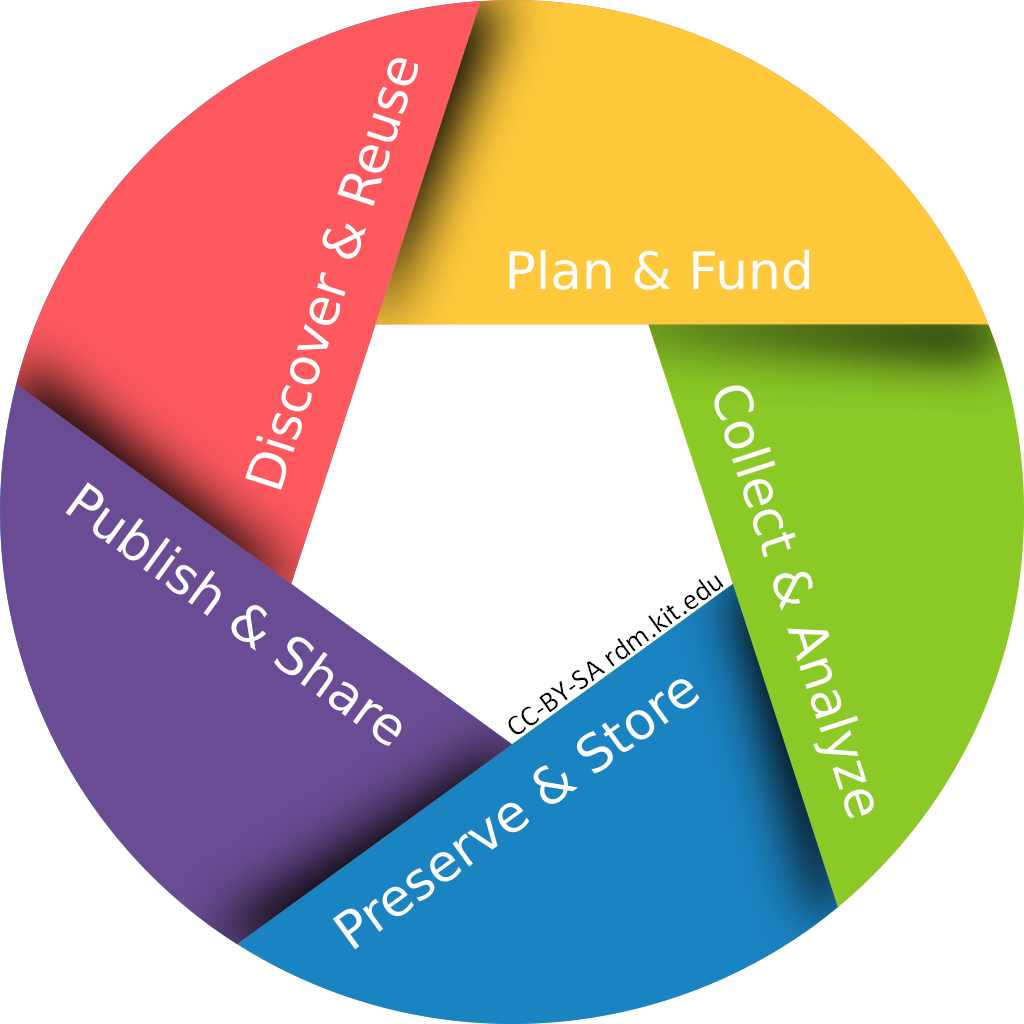
Planning
Research data plays a crucial role already at the planning stage before your project actually begins. Before applying for project funding you need to account for various data-related aspects:
- What data will you need for your research? Are there any datasets already available and, if so, is it possible to reuse them and on what conditions?
- Are you going to collect or generate any data yourself? What type of data and how much? How are you going to do it?
- How many resources (time, money, staff) will you need to process your data at all stages of the research data life cycle? What tools or infrastructure do you need?
A common mistake is not accounting for how resource-consuming data handling is and that it requires resources at all stages of the research process and not only at the beginning during the collection stage. It can lead to poor project planning when almost all resources are invested into the data collection and generation, and there are not enough resources left to process, prepare or analyse the data after it has been collected. That is why it is crucial to have a research data management plan (DMP) already at the planning stage – and update it later as the project grows. A DMP outlines all the main aspects of data handling at each stage of the data life cycle in your project. It helps you to plan all the necessary steps of your RDM and not forget anything important.
Funding agencies often require a DMP as one of the documents in their standard application package. It is necessary as, on the one hand, it is important for them to see that a researcher has a plan in regard to their data and, on the other hand, they also need to take data handling costs into account early on as they can be a significant expenditure item. Planning your RDM well before the project begins is not a formality, but a necessity that can influence the success of the whole research endeavour.
Data collection and analysis
The data collection and analysis stage is often the most time- and resource-consuming, involving a lot of invisible work. In theory, going to the archive and taking some pictures for a quick Transkribus run-through sounds easy, but in practice, it is always more complicated: you need to ensure the quality of the pictures, think about data formats, where you store your data and how you organise your files. Even if the tools you are going to use work perfectly well for you and do not need any training or fine-tuning, your data may still require considerable preparation, cleaning and pre- and post-processing.
Preserve and store
During the preserve and store stage the data needs to be prepared for archiving. Both the German Research Foundation and the Max Planck Society require research data to be available for a minimum period of ten years (Max Planck Gesellschaft, 2021). To achieve this, data needs to be prepared in a certain way which may involve different measures, from quality assurance of data and file format conversions to creating metadata and documentation. Even if the data cannot be published openly due to some legal and ethical restrictions (remember the Open Science principle ‘as open as possible, as closed as necessary’ from my previous blog post?), it must be archived in a closed repository with limited access rights. For example, Max Planck Society recommends their researchers use Keeper to archive data after their projects’ end.
Publish and share
If there are no legal and ethical restrictions speaking against publishing and sharing data with others, then data needs to be published as open data. In that way not only can it be reused by others, but also cited and given credit for. Which repository to choose, what the ups and downs of individual repositories are, what licence to assign or how to get a DOI, are all important questions arising at this stage.
Data recovery and reuse
The data discovery and reuse stage is an important aspect of Open Science, as sharing your results and your data can accelerate scientific progress, link knowledge, help join efforts and lead to better and faster knowledge discovery and production. To make your data discoverable and potentially reusable for others, certain RDM aspects such as describing your dataset with rich metadata (What is your data about? What does it contain? Where does it come from? How was it collected?), using sustainable file formats and (meta)data standards should be taken care of. To enable others to find your data, it is also a good idea to link your data to your publication, be it a book or a journal article, or maybe even accompany your dataset with a data paper in one of the data journals like the Journal of Open Humanities Data, for example.
Your Guide through the Data Life Cycle: the Data Management Plan
As you can see from this brief overview, there are a lot of data-related questions coming up along the way of the data life cycle. Writing a DMP can help you to account for various aspects of your research data management. Of course, it is not possible to plan all aspects of data management at the time of applying for your project’s approval and funding. However, the idea behind the data management plan is that it is a living document that is updated continuously throughout the research project. As your project grows and changes, so does your DMP: it aims to guide you through your data journey. Funding agencies, universities and other institutions often have their own DMP templates which they recommend for use. However, if there are none, you can start by looking around here.
Coming up next in Part 3: Metadata and FAIR principles.
References:
Deutsche Forschungsgemeinschaft. (2025). Guidelines for safeguarding good research practice. Code of conduct.
Kindling, M., & Schirmbacher, P. (2013). „Die digitale Forschungswelt“ als Gegenstand der Forschung / Research on Digital Research / Recherche dans la domaine de la recherche numérique. Information – Wissenschaft & Praxis, 64(2-3).
Max Planck Gesellschaft. (2021). Responsible acting in science: Rules of conduct for good scientific practice – How to handle scientific misconduct.
Milligan, I. (2022). The Transformation of Historical Research in the Digital Age. Cambridge: Cambridge University Press.
Freie Universität Berlin. (2022, August 10). What is research Data? https://www.fu-berlin.de/en/sites/forschungsdatenmanagement/ueber-forschungsdaten/forschungsdaten/index.html
Wilkinson, M. D., Dumontier, M., Aalbersberg, Ij. J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J.-W., da Silva Santos, L. B., Bourne, P. E., Bouwman, J., Brookes, A. J., Clark, T., Crosas, M., Dillo, I., Dumon, O., Edmunds, S., Evelo, C. T., Finkers, R., & Gonzalez-Beltran, A. (2016). The FAIR Guiding Principles for Scientific Data Management and Stewardship. Scientific Data, 3(1).
Feature image: Server at mpilhlt © Christiane Birr
Cite as: Solonets, Polina: A Researcher’s Guide to the Data Life Cycle – Love Your Data Blog Series Part 2, legalhistoryinsights.com, 28.05.2025, https://doi.org/10.17176/20250701-132603-0
