


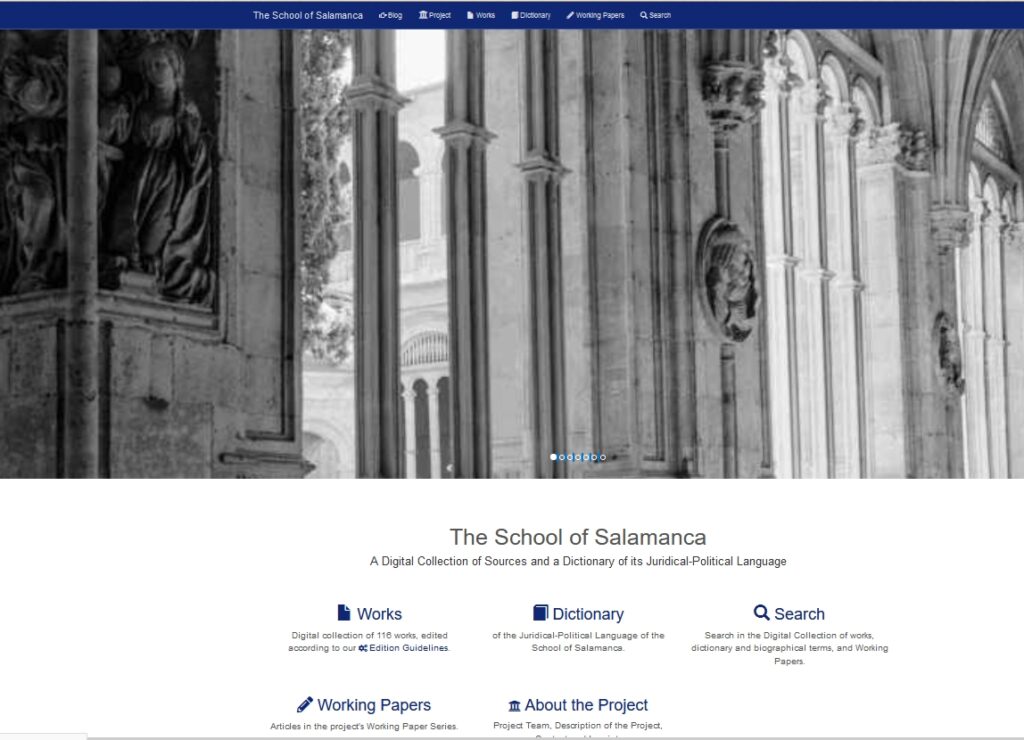
Nicht zum ersten Mal befindet sich das Vermitteln und Speichern von Wissen im Umbruch: längst arbeiten Wissenschaftlerinnen und Wissenschaftler ebenso mit digitalen wie analogen Werkzeugen, und schnell haben wir uns daran gewöhnt, Informationen sofort und unkompliziert im Internet zu finden. Das gilt auch für die Suche nach historischen Drucken, für die früher ein Gang in die Bibliothek unabdingbar war. Weltweit haben Bibliotheken auf diese Veränderungen mit großen Digitalisierungsprogrammen reagiert; inzwischen droht in Vergessenheit zu geraten, was nicht im Netz verfügbar ist. In dieser ebenso weitläufigen wie unübersichtlichen Digitalisierungslandschaft wächst auch das Bedürfnis nach Orientierung, nach Landmarken, die es erlauben, Informationen und Quellen zu spezifischen Themen einfach und zuverlässig zu finden und nachhaltig zu nutzen.
Einen solchen Anlaufpunkt für die Forschungen zur frühneuzeitlichen Scholastik in den Iberian Worlds zu schaffen: daran arbeitet das Projekt Die Schule von Salamanca. Eine digitale Quellensammlung und ein Wörterbuch ihrer juristisch-politischen Sprache. Das Langzeitprojekt wird von der Union der Akademien der Wissenschaften gefördert; für seine Durchführung kooperieren die Akademie der Wissenschaften und der Literatur Mainz, die Goethe-Universität Frankfurt a.M. und das Max-Planck-Institut für Rechtsgeschichte und Rechtstheorie, Frankfurt a.M. Das Projekt wird der internationalen Forschungsgemeinschaft in einer digitalen Quellensammlung über 100 wichtige Werke von Autoren der Schule von Salamanca zur Verfügung stellen; im Moment sind 28 digitale Editionen mit fachwissenschaftlich durchgesehenen Volltexten, 4 Werke in Transkriptionen und weitere 48 Werke als durch Metadaten erschlossene Digitalisate online und für jedermann zugänglich.
Nachdem damit ein großer Teil des Quellenkorpus verfügbar ist, rückt nun das andere Ziel des Projekts in den Mittelpunkt der Projektaktivitäten: die Arbeit an einem Nachschlagewerk, mit dem zentrale Begriffe der politisch-juristischen Sprache der Schule von Salamanca erschlossen werden. Die ersten zwei Artikel sind vor kurzem veröffentlicht worden.
Digitale Quellensammlung und Wörterbuch gehen in vielfacher Hinsicht neue Wege. Die Quellensammlung enthält hochwertige Digitalisate, die durch Metadaten wie ein verlinktes Inhaltsverzeichnis für den Gebrauch handhabbar gemacht werden. Vor allem aber ermöglichen die Volltext-Editionen Suchen über das gesamte Textkorpus hinweg. Die Artikel im Nachschlagewerk sind durch Verlinkungen untereinander und mit der digitalen Quellensammlung verbunden und erlauben es, direkt auf die zitierten Passagen in den Editionen zuzugreifen. Auf beiden Ebenen – Quellensammlung und Nachschlagewerk – werden Methoden der digitalen Geisteswissenschaften eingesetzt und weiterentwickelt, die für die Arbeit mit frühneuzeitlichen Texten zahlreiche Herausforderungen und Chancen bieten.
Digitale Quellensammlung
Die Digitale Quellensammlung enthält Volltexte und Digitalisate von zentralen Texten der Schule von Salamanca sowie wichtiger Referenzwerke, auf die sich die salmantiner Autoren bei der Abfassung ihrer Werke stützten. Die Digitalisate sind überwiegend speziell für das Projekt angefertigt worden, hochauflösend und mit Metadaten erschlossen. Alle Digitalisate sind auf Vollständigkeit und Qualität überprüft; etwaige Fehler im ursprünglichen Druck, etwa bei der Nummerierung der Seiten, sind protokolliert.
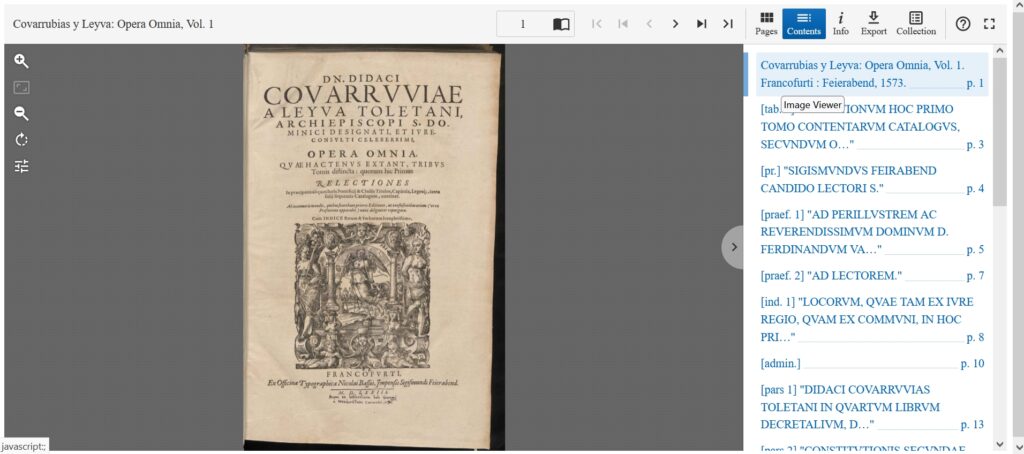
Zusätzlich werden alle Digitalisate transkribiert und aufwändig aufbereitet. Die Transkription erfolgt durch externe Dienstleister auf der Grundlage von detaillierten, vom Projektteam erstellten Erfassungsanweisungen. Das konkrete Procedere richtet sich dabei nach Druckbild und Layout (Spalten, Glossen, Kursivdruck etc.), Papierqualität und weiteren Eigenschaften des jeweiligen digitalisierten Buches. In vielen Fällen kann die grundlegende Texterfassung durch OCR erfolgen, bedarf dann aber einer aufwändigen händischen Nacharbeit. Häufig aber erfordern die Vorlagen ein rein manuelles Verfahren, das sog. double keying, bei dem zwei Typistenteams unabhängig voneinander den gesamten Text erfassen und der Abgleich dieser zwei Versionen dazu dient, Übertragungsfehler aufzuspüren und zu berichtigen. Für jeden Band wird in Absprache mit den Dienstleistern, die je auf ein Verfahren der Texterfassung spezialisiert sind, ermittelt, welche Methode zur Anwendung kommen soll.
Liegen die Volltexte erst einmal vor, werden für die digitale Edition, die sog. Lesefassung, Abbreviaturen und Sonderzeichen aufgelöst, die den frühneuzeitlichen Druckern Platz und Geld sparten, den modernen Leser aber in seinem Lesefluss erheblich stören können. Im Unterschied zu dieser augenfälligen Bearbeitung der Texte ist ein Großteil der Arbeit, die in einer digitalen Edition steckt, für den nicht in den digitalen Geisteswissenschaften geschulten Blick unsichtbar. Das gilt ganz besonders für die aufwändige manuelle Strukturauszeichnung und Ausstattung der Texte mit Metadaten, die für die erweiterten, nur digital möglichen Nutzungsarten der Texte unabdingbar sind.
Wird zum Beispiel in einem Wörterbuchartikel ein in der Quellensammlung vorhandenes Werk zitiert, führt der Verweis direkt zu der zitierten Stelle – das erfordert eine detaillierte Auszeichnung, die es möglich macht, auf jeden strukturellen Abschnitt eines umfangreichen Werkes gezielt zuzugreifen. Ebenfalls unsichtbar sind die Grundlagen der Volltextsuche, die erhebliche Vorteile gegenüber herkömmlichen Suchen, etwa in Word-Dokumenten oder pdf-Dateien mit OCR-Text, bietet. Die Suche erfolgt in den lateinischen und spanischen Texten lemmatisiert, d.h. eine Suche nach „lex“ bringt auch Treffer zu „legis, lege, legem, leges, legum, legibus“. Auch orthografische Besonderheiten des frühneuzeitlichen Latein bzw. Spanisch werden weitgehend durch die Suche aufgefangen: so bringt die Suche nach „verbum“ auch Treffer für „uerbum“ oder „uerbvm“. Außerdem umfasst die Suche nicht nur einzelne Werke, sondern das gesamte Corpus.
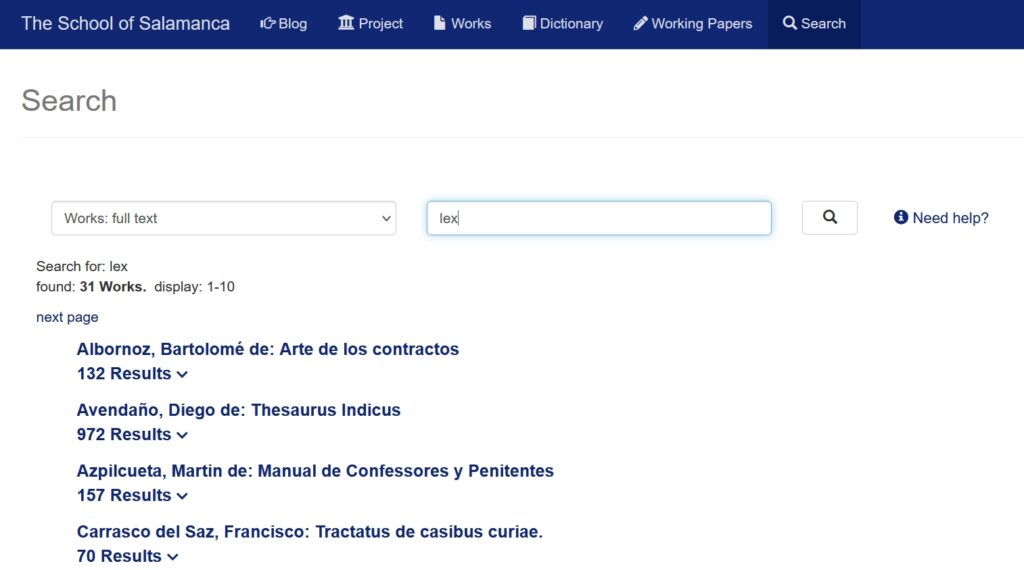
Damit sind die Möglichkeiten einer digitalen Edition noch längst nicht ausgeschöpft, und diese gehen über das Aufgabenportfolio des Salamanca-Projekts hinaus. Deshalb ist es besonders wichtig, die Volltexte als Forschungsdaten auch anderen Projekten und Forschenden zur Verfügung zu stellen; sie stehen deshalb im xml und .txt-Format zum Download bereit und können so als Ausgangspunkt für die Anwendung weiterer Instrumente dienen, die in den letzten Jahren in den digitalen Geisteswissenschaften entwickelt worden sind (topic modelling, stylometrics, verschiedene Verfahren des text mining, usw.) oder gegenwärtig und zukünftig entwickelt werden. Die Volltexte können aber auch von menschlichen Lesern heruntergeladen werden, wenn man zum Beispiel die Texte im pdf-Format auf dem eigenen Rechner speichern und unabhängig von einer Internetverbindung nutzen möchte.
Wörterbuch der juristisch-politischen Sprache der Schule von Salamanca
Die so aufbereiteten und durchsuchbaren Quellen stehen nun auch als Grundlage für das Abfassen der Artikel für das Wörterbuch der juristisch-politischen Sprache der Schule von Salamanca zur Verfügung. Die Artikel sollen wichtige Begriffe eng an den Quellen orientiert erschließen und über ihre Verlinkungen und Verbindung mit dem Quellenkorpus in die Texte hineinführen. Die lateinischen und spanischen Lemmata sind den Quellen selbst entnommen; ihre Auswahl ist das Ergebnis eines mehrstufigen Prozesses, der quantitative Auswertungen von Texten und Indices ebenso umfasste wie deren qualitative Revision im Rahmen von mehreren Workshops mit Expertinnen und Experten aus verschiedenen akademischen Disziplinen. Im Blick war dabei immer das konkrete Ziel des Projekts, nämlich die juristisch-politische Sprache zu erschließen. Die Artikel sollen quellennah sein; ein Anliegen ist es u.a., die Binnendiskussionen der Schule von Salamanca aufzuzeigen und in ihrer konkreten historischen Einbettung nachvollziehbar zu machen.
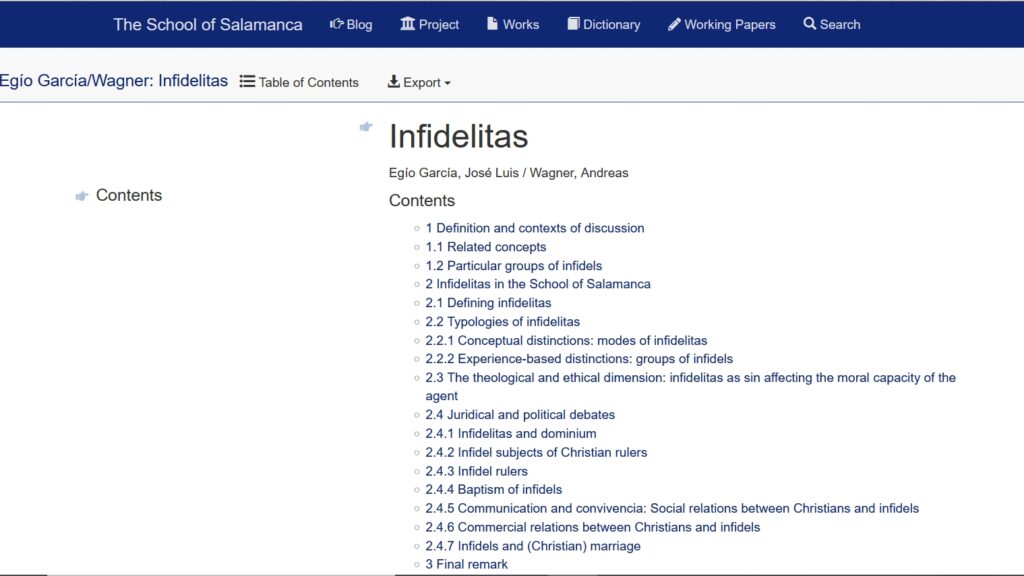
Chancen und Risiken
Die Chancen eines solchen Projekts liegen auf der Hand: Die Digitalisate, digitalen Editionen und Metadaten sowie die Beiträge zum Nachschlagewerk werden unmittelbar, kostenlos, ohne räumliche und zeitliche Einschränkung zugänglich gemacht. Keine Bibliothek oder digitale Sammlung bietet eine solche Auswahl und Anzahl von einschlägigen Texten, erst recht nicht in aufbereiteter Form. Garantiert kostenfreier und dauerhafter Zugang zu in ihrer Qualität überprüften Digitalisaten, feste und dauerhafte Zitierlinks, transkribierte Volltexte, die Durchsuchbarkeit des gesamten Corpus, Lemmatisierung und die Nachnutzbarkeit der Forschungsdaten durch externe Interessierte sind nur einige der Vorteile gegenüber existierenden digitalen Sammlungen oder gar Google Books.
Die Texte fungieren zugleich als Forschungsdaten, die als Ausgangsmaterial für weitere, vom Projekt unabhängige Fragestellungen der digitalen Geisteswissenschaften dienen können. Aber auch eine klassisch-individuelle Forschungsarbeit, die auf close reading, Textanalyse und historischer Kontextualisierung beruht, wird durch die Suchmöglichkeiten und die interdisziplinäre Information des Wörterbuchs auf eine neue Grundlage gestellt. Zudem können Quellensammlung und Nachschlagewerk den in verschiedenen Disziplinen und Sprachgemeinschaften beheimateten Forscherinnen und Forschern ein Forum bieten.
Dieses Projekt liegt uns gerade deshalb besonders am Herzen, weil es uns ermöglicht, Instrumente der digitalen Geisteswissenschaften für die Geschichte von Recht, Politik und Philosophie zu nutzen und zu entwickeln. Die Volltexte, die wir in ihm mit erheblichem Aufwand produzieren, können erst und nur durch diese Vor- und Aufbereitung für neue Analysemethoden genutzt werden: von einer Inhaltsanalyse bis zu der noch vor einigen Jahren unmöglich scheinenden, inzwischen aber nicht mehr gänzlich unrealistischen Möglichkeit, automatische Übersetzungen von Texten in akzeptabler Qualität anzufertigen. Dazu gehören für uns auch Überlegungen, unsere Daten als Trainingsgrundlage für eine AI-Instanz anzuwenden, die uns bei der bislang aufwändigsten Herausforderung helfen könnte: der manuellen Textkorrektur. Trotz der vergleichsweise hohen Präzision der manuellen und maschinellen Transkriptionen und manueller und algorithmengestützter Fehlerkorrektur ist es zur Zeit noch unmöglich, in einem über 77,5 Millionen Zeichen umfassenden Textkorpus (soweit die Zählung der bereits existierenden digitalen Editionen) völlig fehlerfreie Texte herzustellen; zur Klärung von Zweifelsfällen kann man deswegen die Transkriptionen mit den für jeden Abschnitt verfügbaren digitalen Faksimiles abgleichen.
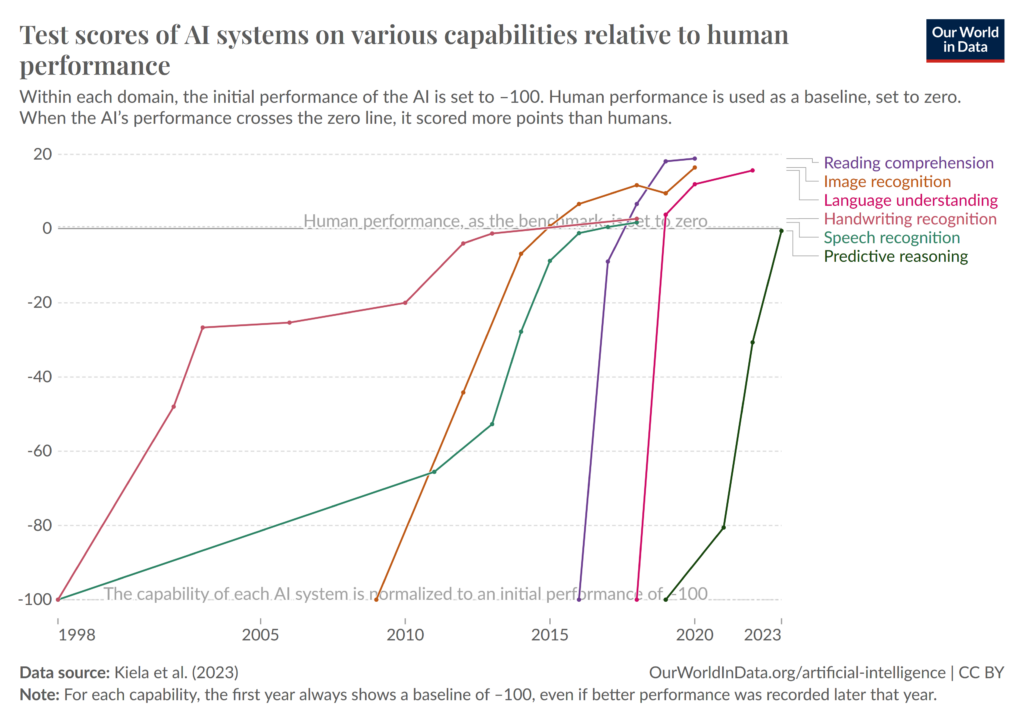
Textedition mit Hilfe von OCR und AI, digitale Analysetools zur Inhaltserfassung moraltheologischer Texte des 16. Jahrhunderts, automatische Übersetzungen schwieriger lateinischer Abhandlungen – all das vermag bei manchen Beobachtern geradezu Empörung hervorzurufen. Das taten die ersten Eisenbahnen auch. Die Warnungen vor Kontextverlust, die Angst vor der Entwertung (hilfs)wissenschaftlicher Fähigkeiten und die Frage nach einer nachhaltigen Infrastruktur müssen natürlich ernstgenommen werden: technische Umbrüche verunsichern, begeistern, empören und faszinieren zugleich, und jede Neuerung birgt neben Chancen auch Gefahren. Doch die neuen Möglichkeiten schlicht zu ignorieren hieße, einen großen Teil unseres kulturellen Erbes der Gefahr des Vergessenwerdens anheim zu geben. Und wenn wir einfach abwarten, bis professionelle kommerzielle Anbieter Projekte entwickeln, „[We] risk turning over not only the historical sources but also entire methodologies to corporations“, wie es vor einigen Monaten in einem Forum im American Historical Review zu Artificial Intelligence and the Practice of History hieß. Auch die Rechtsgeschichte kann wohl nicht anders, als die schier unglaubliche Dynamik der Entwicklung künstlicher Intelligenz zum Anlass zu nehmen, um sich über deren Nutzen nicht nur Gedanken zu machen, sondern an ihrer Nutzbarmachung mitzuwirken – die recht kurze Geschichte der Zunahme der Leistungsfähigkeit Künstlicher Intelligenz dürfte vor Augen führen, wie schnell sich die Leistungsfähigkeit neuer Technologien erhöht (weitere Informationen sowie Nachweise zur Grafik).
Anders als gedruckte Bücher, die, einmal produziert und richtig gelagert, leicht Jahrhunderte überstehen, stellen digitale Editionsprojekte größere Wartungsanforderungen, um nachhaltig verfügbar zu sein. Diese Nachhaltigkeit zu gewährleisten gehört zu den großen Herausforderungen der digitalen Geisteswissenschaften. Auch über diese muss kontinuierlich nachgedacht werden, um strukturelle und institutionelle Lösungen zu finden, die wissenschaftsadäquat sind. Man baut heute nämlich die digitale Infrastruktur für die Zukunft. Die Langzeitvorhaben, die von der Union der Akademien gefördert werden und die sich der Sicherung des kulturellen Erbes mit Mitteln der Digital Humanities verschrieben haben, sind ein privilegierter Ort dafür.
Cite as: Birr, Christiane/Duve, Thomas: Das digitale Nadelöhr: Die Arbeit an einer digitalen Edition im Projekt „Die Schule von Salamanca“, legalhistoryinsights.com, 18.04.2024, https://doi.org/10.17176/20240422-144859-0
 This work is licensed under a
This work is licensed under a 